
Dependence Drives Group Thickness

We are parts of many social units. In those we see as “thick”, we are more okay being partisan and wanting other members to share many loyalties and cultural features with us. In “thin” units, we are instead more tolerant and tend to allow everyone who doesn’t violate basic norms.
Bryan Caplan has a new book You Have No Right To Your Culture, wherein he seems to me to say that we should see nations as relatively “thin” social units, and so be open to more immigration into them. Which made me curious about which kinds of units we see as how thick, and what unit features predict this view.
So I listed nine types of social units: families, clubs, firms, professions, churches, neighborhoods, cities, nations, and world. And I came up with three plausible factors that might predict thickness:
Power - How much power a social unit has over its members.
Competition - How easily might this unit be killed by competition. Which correlates with how many alternative units compete with each one, with how easy it is to leave the unit, and with voluntary entry to the unit. This tends to be stronger for smaller scale units.
Dependence - How much unit members depend on each other, and so have externalities due to other member choices. Which creates more coordination gains within such units. Which induces such units to manage a wider range of aspects of member lives. Which results in members gaining deeper identities from such units, seeing these units as more sacred, discouraging internal diversity, and encouraging equal treatment.
To estimate which factors matter more, I asked six LLMs to give 0-10 scores for each of these nine units re levels of thickness, power, competition, and dependence, and then to do a regression estimating thickness from the three factors.
The next table shows all their coefficients, together with the median across all the LLMs. I also asked for the predicted thickness for nations from their regression model, which is the last row. (The median of those happens to equal the median of nation thickness scores.)
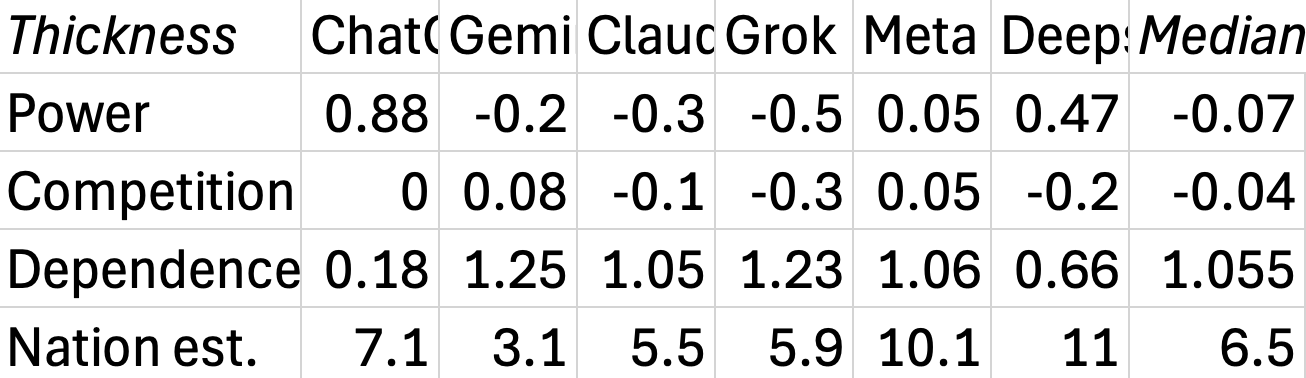
The medians tell a simple story: social unit thickness, i.e.., how okay we are with requiring unit members to share loyalties and cultures, as opposed to tolerating differences, depends little on how much power those units have over us, nor on how much competition those units face, including how easy units are to leave or how voluntary to enter. Thickness is instead mainly seen as resulting from dependence, i.e., feeling that member outcomes depend a lot on choices made by other members. Nations are seen as ~2/3 toward thick on a thin-to-thick scale.
So people wanting to be more careful than tolerant re nation immigrants seems quite predictable, given that people think that nation member outcomes often depend a lot on what other nation members do. Which suggests three ways to change their minds:
Show them that nation member outcomes do not in fact depend so much on what other nation members do.
Convince them to set unit thickness levels on something other than how much unit member outcomes depend on other member actions.
Convince them that the immigrants they worry about are in fact likely to take actions that will give them good outcomes.
I don't understand the strategy of using LLMs to generate the scores. On what basis can we have any confidence in the numbers generated as having any empirical weight at all?
Besides that - what about low dependence contexts that seem extremely thick? e.g. the internet, (discussion forums etc) where tolerance seems extremely low.
Please always cite the exact model your using when you’re using LLM.
In particular : ChatGPT is an outlier here, and I’m not convinced dismissing it (as the median do) is the right call. Is it 5.2 auto ? instant ? thinking ? If auto, did it get routed to instant or thinking ?
What about other models ? Is it Opus 4.5 or Sonnet 4.5 ? Gemini Pro or Flash ?
The negative correlations sounds very fishy, too. Increasing power means decreasing thickness ? What ? Granted, they are very small, but still.