
Noble Abstention

High voter turnout need not be good – not only is voting costly, but ignorant voters can make better candidates less likely to win. Many have noted this last possibility, but I couldn’t find any formal models (i.e., of abstention by varying-info-quality voters) – so I made my own. My results depend on how unequally distributed is voter info; highly unequal info means only a handful should vote, while relatively equal info means most everyone should vote (ignoring voting costs).
Let N voters simultaneously choose to abstain or vote for one of two apriori-equal candidates, based only on which action is more likely to elect the “best” candidate. Each voter gets an independent private binary signal with a chance (1+q)/2 of accurately marking the best candidate. Assume that if we rank voters by signal quality q (so the best voter has rank = 1, the next has rank = 2, etc.), we’ll find quality and rank are related by a power law, q = q1*rank^-power. (Voter signal qualities q>0 are common knowledge.)
The following table shows how the number who do not abstain varies with info-quality power, for N = 10,000 voters, q1=0.1, and for two important cases. In case 1, everyone uses the same q cutoff when deciding if to vote. In case 2, each voter assumes (incorrectly) that no other voter abstains.
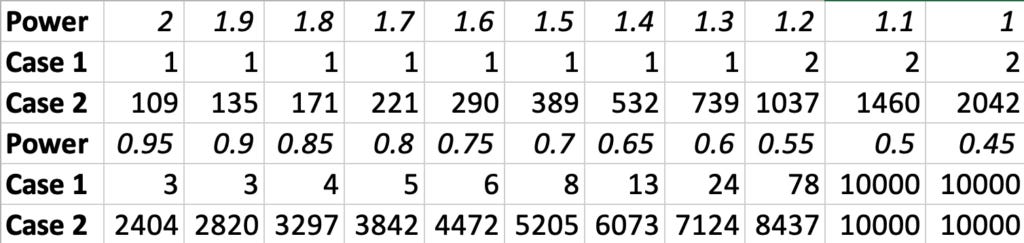
The table shows that for powers above one less than 20% should vote, even if everyone else votes. And if everyone does what they should, for powers above 1/2, almost no one votes, while for powers below 1/2 everyone votes. (This last result holds for any N and q1.)
Similar results probably hold for correlated and non-binary signals. I’m not sure how we could measure voter info inequality, but I’d give at least two to one odds the effective power is above 1/2, meaning few should vote. Of course people vote not just to elect the best candidates overall, but to elect folks good for them personally, even when that hurts others. But this isn’t something we should celebrate or encourage, and most voters see themselves as instead voting to improve society overall.
Large voter turnouts seem to me better understood as overconfidence leading to disagreement – we each think we just know better than others what is good for society. But too few of us can be right on this for most of us to be (epistemically) rational here. So I celebrate the noble abstainers, those willing to admit by staying home that their vote would probably just make things worse – we could use a lot more such folks.
Added 16Sep: Any model with independent signals must either have large electorates get very certain to make the right choice, or must have voter signals get very weak with high rank. A correlated signals model would be more realistic here.
Added 02Nov20: Here’s the actual spreadsheet I used for calculations.
Mike makes a good point in bringing up correlation. If you assume that voters are uncorrelated, most models will probably conclude that everyone should vote. The main problem with uninformed voters is when their votes are correlated (because of eg. advertisements, cultural biases, or systematic errors in reasoning).
Since your model doesn't mention correlations, and yet comes up with small numbers of voters being optimal, I have to continue to suspect that you aren't taking variance into account correctly.
> Let N voters simultaneously choose to abstain or vote for one of two apriori-equal candidates, based only on which action is more likely to elect the “best” candidate.
This seems like a weird thing to do, and seems to be a completely backwards way of looking at what elections actually do in democracies. If you have two groups of people who are in conflict with eachother, one way you can resolve said conflict is through a vote -- a cynical way of looking at this is 'who can outbreed the other and get the more votes' but in practice this really is part of what democracies actually do - they serve as a non-violent means of resolving inter-group conflict.
In that case there is no 'best candidate' - there is your candidate, and my candidate. The question of which 'tribe' you and i are in becomes more salient -- the more you define your tribe as 50%+1 you can have power . Whether it's rich vs poor, white vs black, men vs women, people who work in the entertainment industry vs people who work in the tech industry...these issues hash themselves out at the ballot. It's messy but it is less messy than say a gang or civil war.
Where does this kind of analysis of 'best candidate' lead us in such a case? It's the story of what happens if voters cooperate. But clearly, they are *competing* with eachother.
Perhaps what is needed is a model that, within this conflict between groups, then has to come up with a marginally optimal number of voters. But wouldn't that be "as much as possible" to offset the competing groups? Seems like it would unless there's some kind of social more keeping only small numbers of a majority voting it'll always be 100% (for example -- religious people not voting until they were politically polarized to do by previous false majorities of more secular types 'going too far')