
How Deviant Recent AI Progress Lumpiness?

I seem to disagree with most people working on artificial intelligence (AI) risk. While with them I expect rapid change once AI is powerful enough to replace most all human workers, I expect this change to be spread across the world, not concentrated in one main localized AI system. The efforts of AI risk folks to design AI systems whose values won’t drift might stop global AI value drift if there is just one main AI system. But doing so in a world of many AI systems at similar abilities levels requires strong global governance of AI systems, which is a tall order anytime soon. Their continued focus on preventing single system drift suggests that they expect a single main AI system.
The main reason that I understand to expect relatively local AI progress is if AI progress is unusually lumpy, i.e., arriving in unusually fewer larger packages rather than in the usual many smaller packages. If one AI team finds a big lump, it might jump way ahead of the other teams.
However, we have a vast literature on the lumpiness of research and innovation more generally, which clearly says that usually most of the value in innovation is found in many small innovations. We have also so far seen this in computer science (CS) and AI. Even if there have been historical examples where much value was found in particular big innovations, such as nuclear weapons or the origin of humans.
Apparently many people associated with AI risk, including the star machine learning (ML) researchers that they often idolize, find it intuitively plausible that AI and ML progress is exceptionally lumpy. Such researchers often say, “My project is ‘huge’, and will soon do it all!” A decade ago my ex-co-blogger Eliezer Yudkowsky and I argued here on this blog about our differing estimates of AI progress lumpiness. He recently offered Alpha Go Zero as evidence of AI lumpiness:
I emphasize how all the mighty human edifice of Go knowledge … was entirely discarded by AlphaGo Zero with a subsequent performance improvement. … Sheer speed of capability gain should also be highlighted here. … you don’t even need self-improvement to get things that look like FOOM. … the situation with AlphaGo Zero looks nothing like the Hansonian hypothesis and a heck of a lot more like the Yudkowskian one.
I replied that, just as seeing an unusually large terror attack like 9-11 shouldn’t much change your estimate of the overall distribution of terror attacks, nor seeing one big earthquake change your estimate of the overall distribution of earthquakes, seeing one big AI research gain like AlphaGo Zero shouldn’t much change your estimate of the overall distribution of AI progress. (Seeing two big lumps in a row, however, would be stronger evidence.) In his recent podcast with Sam Harris, Eliezer said:
Y: I have claimed recently on facebook that now that we have seen Alpha Zero, Alpha Zero seems like strong evidence against Hanson’s thesis for how these things necessarily go very slow because they have to duplicate all the work done by human civilization and that’s hard. …
H: What’s the best version of his argument, and then why is he wrong?
Y: Nothing can prepare you for Robin Hanson! Ha ha ha. Well, the argument that Robin Hanson has given is that these systems are still immature and narrow, and things will change when they get general. And my reply has been something like, okay, what changes your mind short of the world actually ending. If your theory is wrong do we get to find out about that at all before the world does.
(Sam didn’t raise the subject in his recent podcast with me.)
In this post, let me give another example (beyond two big lumps in a row) of what could change my mind. I offer a clear observable indicator, for which data should have available now: deviant citation lumpiness in recent ML research. One standard measure of research impact is citations; bigger lumpier developments gain more citations that smaller ones. And it turns out that the lumpiness of citations is remarkably constant across research fields! See this March 3 paper in Science:
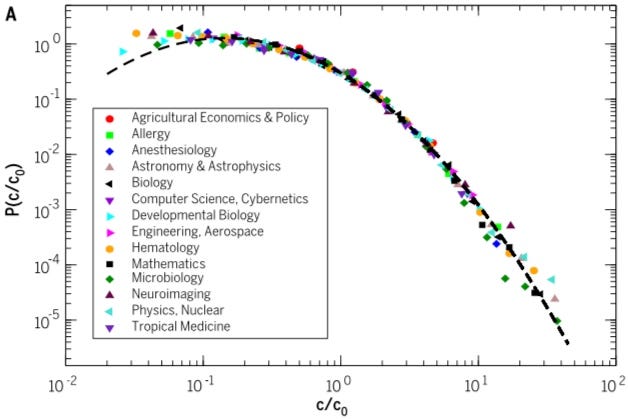
The citation distributions of papers published in the same discipline and year lie on the same curve for most disciplines, if the raw number of citations c of each paper is divided by the average number of citations c0 over all papers in that discipline and year. The dashed line is a lognormal fit. …
The probability of citing a paper grows with the number of citations that it has already collected. Such a model can be augmented with … decreasing the citation probability with the age of the paper, and a fitness parameter, unique to each paper, capturing the appeal of the work to the scientific community. Only a tiny fraction of papers deviate from the pattern described by such a model.
It seems to me quite reasonable to expect that fields where real research progress is lumpier would also display a lumpier distribution of citations. So if CS, AI, or ML research is much lumpier than in other areas, we should expect to see that in citation data. Even if your hypothesis is that only ML research is lumpier, and only in the last 5 years, we should still have enough citation data to see that. My expectation, of course, is that recent ML citation lumpiness is not much bigger than in most research fields through history.
Added 24Mar: You might save the hypothesis that research areas vary greatly in lumpiness by postulating that the number of citations of each research advance goes as the rank of the “size” of that advance, relative to its research area. The distribution of ranks is always the same, after all. But this would be a surprising outcome, and hence seems unlikely; I’d want to see clear evidence that the distribution of lumpiness of advances varies greatly across fields.
Added 27Mar: More directly relevant might be data on distributions of patent value and citations. Do these distributions vary by topic? Are CS/AI/ML distributed more unequally?
Compare things to the first nuclear bomb. There were many small improvements that each didn’t result in a working bomb. The effect on the maximum yield of a nuclear device was 0 for each of them individually. But when put together, we suddenly went from 0 to 22 kiloton TNT.
It hasn't been refuted by building a full artificial intelligence/consciousness.