
How and When to Listen to the Crowd
by Daniel Reeves and David Pennock
If you think the probability that something will happen is 90% and then you find out that your friend said 30%, what should your new assessment be? What if the average of ten of your friends’ assessments was 30%? Should you stick to your guns? Acquiesce to your friends? Average your and your friends’ assessments? If so, should you use an algebraic or geometric average? Weight the assessments? How? Should you average the probabilities, the odds [p/(1-p)], or the log odds? Or should you update Bayesian style?
Most people would shift their assessment at most halfway toward 30%, to something between 60-90%. But the theory on “not agreeing to disagree” tells us that shifting even further may often be warranted. In this post, we don’t weigh in on theoretical arguments at all. Instead we present empirical evidence showing that — at least in one narrow setting — there is a clear benefit for almost everyone to lean heavily toward the crowd’s assessment rather than one’s own assessment, even more so as the number of other assessments grows.
This post follows up on a description of the wisdom-of-crowds effect seen in an online sports prediction contest called ProbabilitySports. Thousands of participants give probability assessments for hundreds of US National Football League games and are scored in a way that encourages them to be as accurate as possible. To be specific, contestants are rewarded according to the quadratic scoring rule.
The following figure shows the average per-game scores of groups of participants of increasing size. On the left is the average score for a single randomly selected player in 2004. Rightmost is the average score for “the crowd” (i.e., everyone). In between are the average scores of random groups of the specified size. The average individual received a badly negative score, and the average group of two remained negative. Groups of three or more scored positively, improving quickly and monotonically as the group size increases.
Each number on top of a bar is the percentage of individuals that perform better than groups of the specified size. For example, 64% of people scored above the average score, 16% of people scored better than the average group of five, and only 5% of people scored better than the average group of ten.
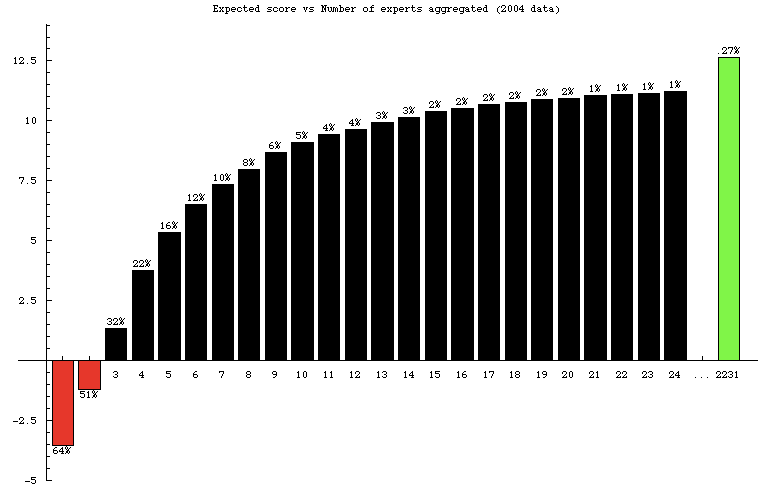
Clearly, for most people, averaging their own assessment with others is the right strategy. The percentages can be interpreted as follows: Given access to, for example, nine other random assessments, you should ignore them only if you believe you are among the top five percent of participants. And only the cream of the cream — 6 of the 2231 players — outperformed the crowd: You are justified to ignore the crowd only if you believe you’re in the 99.73 percentile of predictors.
One thing to notice is that the largest incremental improvement comes with the first few additional assessments, and it doesn’t take very many randomly selected other participants before reaching the point of diminishing returns. Also note that these results are for random groups. If there is reason to believe that your information may correlate with your friends’ information, averaging with your friends may be less effective in general than averaging with random strangers.
As for how to aggregate probabilities, the above analysis assumes a simple arithmetic mean and we have confirmed empirically that this choice beats geometric mean, root-mean-square, and every power mean in between, regardless of the number of probabilities being aggregated. Arithmetic mean also beats any power mean of the odds, an alternative probability aggregation method recently suggested by Chris Hibbert. Interestingly, we do find evidence that Chris’s method works better than arithmetic mean if one can somehow identify the best experts ahead of time and average only those “expert experts”.
Missing image:
https://uploads.disquscdn.c...
This may not be the best type of contest to analyze this question. Everyone has equal access to all sorts of handicapping data for NFL games. To win this type of game, a contestant has to be at least as good as the conventional wisdom. There is no use in selecting the most "probable" probabilities because out of 1000s of contestants, many people will do the same thing, plus get lucky on a few other games. You need to start with the obvious games, then bet on several unlikely outcomes. In other words, with so many contestants some people will naturally end up out on the tails of the curve, and you need to take some chances to end up there too.
Coming in the middle of the pack wins you nothing, so taking some chances in order to come out on top costs you nothing. Consequently lots of contestants guess "improbable" probabilities on occasions, and the result is that 64% of them are below zero.
Averaging out all the "improbable" guesses people make (and home team biases) would be expected to place relatively high in the pack. But admittedly 7th place is pretty stunning.